
Во многих компаниях не станут спрашивать, что такое структуры данных, сложность алгоритмов (хотя иногда могут спросить ради оценки общей IT-эрудиции). Не нужно будет решать алгоритмы и применять паттерны проектирования ООП. Скорее всего, не придётся рассказывать про устройство и архитектурные особенности базы данных, на которую вас зовут работать. Помните то чувство фрустрации, когда вы не знали, что содержат таблицы orders_final_v1?
Например, вы сделали новую версию модели лучше предыдущей (метрики модели лучше), но в то же самое время пришёл экономический кризис и люди перестали покупать ваш продукт (упала выручка). Если бы в этой ситуации вы не замеряли показатели модели, то могли бы подумать, что из-за новой версии модели упала выручка, хотя упала она не из-за модели. Пример довольно простой, но хорошо описывает почему нужно разделять метрики модели и бизнеса. Дата-инженер принимает участие в развёртывании и настройке существующих решений, определении необходимых ресурсных мощностей для программ и систем, построении систем сбора метрик и логов.
– Но самое главное, в работе нашей группы – постоянно следить за новинками, внедрять их, быть на волне. Способность к обучению в huge data разработке я бы поставил выше всего. Именно тогда в Париже появился Комитет по данным для науки и техники при Международном научном совете. Однако, долгое время выражение «data science» можно было услышать только в узких кругах статистиков и ученых.
Я подробно расскажу про эти данные и покажу первые результаты простых моделей, которые были получены в рамках моей стажировки в центре медицины Sber AI Lab. Чтобы облегчить выполнение этих задач, можно использовать open supply решения. Мы собрали компактный список таких инструментов, включающий платформы для визуализации данных и другие утилиты, облегчающие работу разработчиков. Процессы структурирования, изменения типа, очищения данных и поиска аномалий во всех этих алгоритмах. Предварительная обработка может быть частью либо системы машинного обучения, либо системы конвейерной обработки данных. Разработка механизма хранения и доступа к данным — еще одна частая задача дата-инженеров.
Профессия Координатор Образовательной Онлайн-платформы — Задачи, Преимущества И Недостатки Работы, Образовательные Программы
За удобными юзер интерфейсами и результатами кейсов, скрывается большой труд ребят из отдела социальной аналитики. Меня зовут Александр Троицкий, я автор канала AI для чайников, и сегодня я расскажу про самую популярную у дата саентистов модель машинного обучения – градиентный бустинг. Эту статью я напишу нетехническим языком, потому что сам не технарь и не математик. Надеюсь, что она поможет узнать о NLP тем, кто не сталкивается с AI в продуктах на ежедневной основе. Чаще всего их используют, чтобы сравнивать модели между собой, абстрагируясь от бизнес метрик. Если вы будете смотреть только на бизнес-метрики (например, NPS клиентов или выручка), то можете упустить из-за чего реально произошло снижение или повышение показателей вашего бизнеса.

Существует совсем немного инструментов, которые используются повсеместно. Поэтому придётся изучить много разных фреймворков и баз данных, но пользоваться только ограниченным набором в зависимости от конкретного проекта. Другими словами, делаем так, чтобы им было проще работать с большими объемами данных, с кластерными и операционными системами, – рассказывает Шерзод Гапиров, руководитель группы разработки в отделе аналитики Eastwind.
Существует множество платформ, предлагающих онлайн-курсы по разработке моделей big information. На этой платформе можно найти различные курсы, связанные с большими данными и разработкой моделей, которые предлагаются ведущими университетами и специалистами в данной области. Одной из основных обязанностей разработчика моделей huge data является анализ требований заказчика и разработка подходящей модели на основе доступных данных. Он должен уметь проводить анализ данных, искать взаимосвязи и закономерности, а также предсказывать будущие тренды и события. Сфера huge information постоянно развивается, и разработчики моделей huge information имеют возможность постоянно учиться и совершенствоваться.
Как Маскировка Данных Спасает Вашу Приватность
В каждой компании – свои специфические задачи, к решению которых нужно подходить индивидуально. Поэтому, после освоения базы, вам придется постоянно совершенствоваться. – Чтобы работать в анализе больших данных, нужно иметь скилы из разных областей, – добавляет Михаил Чернышев, группа анализа данных Eastwind. Не факт, что модель, которую ты придумаешь, сработает с первого раза. Современные методы бесконтактной оценки медицинских параметров позволяют по видеопотоку с камеры определять, какой у человека пульс.
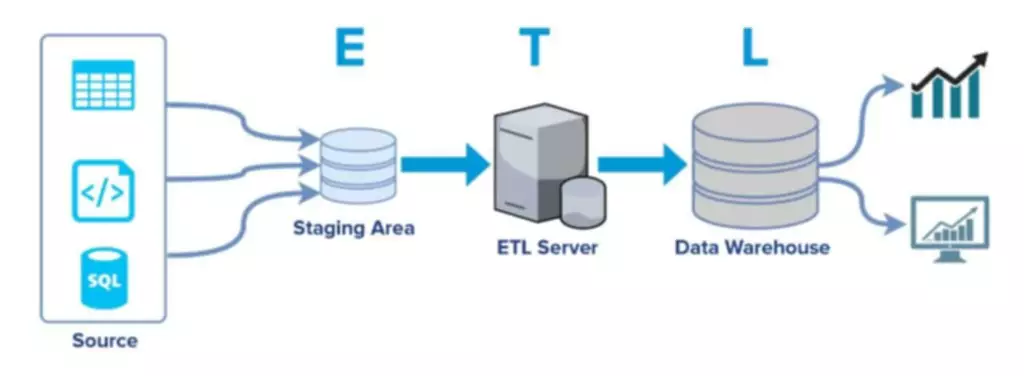
Моя цель – осветить некоторые ключевые особенности в архитектуре ClickHouse и в том, как он хранит данные. Так что сейчас как раз просто шикарный момент, чтобы войти в профессию Data Engineering с нашим курсом Data Engineering и стать востребованным специалистом в любом серьёзном Data Science проекте. Пока рынок растёт настолько быстро, то специалист big data возможность найти хорошую работу, есть даже у новичков. Дальнейшее развитие для специалистов Big Data Engineers тоже довольно разнообразное. Можно уйти в смежные Data Science или Data Analytics, в архитектуру данных, Devops-специальности. Можно также уйти в чистую разработку на Python или Scala, но так делает довольно малый процент спецов.
Какие Навыки И Обязанности Huge Information Engineer?
Разработка системы, которая удовлетворяет этим требованиям, и есть задача инженера данных. Не смотря на эти недостатки, разработка моделей big information является перспективной и высокооплачиваемой профессией с большими возможностями для карьерного развития. Дата инженеры должны обладать сильными коммуникативными навыками. Также Big Data Engineer должен чувствовать себя комфортно во время собеседований и сотрудничества с экспертами в предметной области, бизнес-аналитиками и группами специалистов по анализу данных. Это поможет выявить, проверить, оценить и расставить приоритеты бизнес-требований и операционных требований.
- Обсудим интеграцию таких инструментов, как AirFlow и Spark, с CI/CD пайплайнами, а также создание конфигурационного модуля, позволяющего разработчикам сосредоточиться на моделях, не углубляясь в инфраструктурные детали.
- Кроме того, некоторые платформы предлагают возможность получить сертификат о прохождении курса, который может быть полезен при поиске работы или продвижении по карьерной лестнице.
- Для быстрого доступа к данным часто используются такие системы, как Cassandra, Redis, Elasticsearch или их аналоги.
- В предыдущих тестах на джобу мы не затрагивали интеграцию с Kafka, ведь нам были не важны реальные source и sink.
- Ведь сайентист — это по сути потребитель данных, которые предоставляет инженер.
- Мы собрали компактный список таких инструментов, включающий платформы для визуализации данных и другие утилиты, облегчающие работу разработчиков.
Благодаря гибкости и масштабируемости, они могут быть адаптированы к потребностям различных компаний. Поэтому в сегодняшней статье, специально к старту нового потока курса по Data Engineering, мы разберёмся, кто такой Big Data Engineer, чем он занимается и чем отличается от Data Analyst и Data Scientist. Этот гайд подойдёт людям, которые хотят работать с большими данными и присматриваются к профессии в целом. А также тем, кто просто хочет понять, чем занимаются инженеры данных. Пройти обучение на аналитика Big Data в Москве всех желающих приглашает ЦРК БИ (ЦЕНТР РАЗВИТИЯ КОМПЕТЕНЦИЙ В БИЗНЕС-ИНФОРМАТИКЕ) НИУ ВШЭ. В рамках курсов по программам MBA IT вы получите все необходимые знания и компетенции.
Обязанности разработчика моделей huge data требуют глубокого знания алгоритмов обработки данных, программирования и статистического анализа. Он должен быть готов к постоянному обновлению и совершенствованию своих навыков, чтобы эффективно решать сложные задачи в области massive data. В работе разработчика моделей huge knowledge требуется много времени и усилий для анализа больших объемов данных, а также внимательность и точность в работе.
То есть Big Data Engineer работает со средой, которая включает в себя архитектуру, технологические стандарты, варианты с открытым исходным кодом, процессы подготовки и управления данными. Главная задача Data engineer — построить систему хранения данных, очистить и отформатировать их, а также настроить процесс обновления и приёма данных для дальнейшей работы с ними. Помимо этого, инженер данных занимается непосредственным созданием моделей обработки информации и машинного обучения. Задачи, которые выполняет инженер больших данных, входят в цикл разработки машинного обучения. По окончании обучения студенты могут приступить к работе в качестве разработчика моделей huge information, а также продолжить свое образование, участвуя в магистратуре и докторантуре или проходя специализированные курсы и тренинги. Кроме Coursera, существуют и другие платформы, такие как Udemy, edX и LinkedIn Learning, которые также предлагают онлайн-курсы по разработке моделей huge knowledge.
Как Избежать Отчисления Из Вуза И Сохранить Год Обучения
Мы оценили со всех сторон профессию и подготовили сравнительную таблицу – с какими преимуществами и недостатками сталкивается в своей работе аналитик больших данных. Эти примеры подчеркивают многообразие возможностей https://deveducation.com/ для разработчиков моделей Big Data и важность их работы в создании инновационных решений и продуктов в различных отраслях. Онлайн-обучение позволяет гибко планировать свое время и изучать материалы в удобном темпе.
Кто Такой Аналитик Massive Information, Что Делает И Сколько Зарабатывает
Формальное обучение информатике, математике или инженерным принципам — основа работы любого успешного дата инженера. Big Data Engineer занимаются изучением необходимых концепций, таких как функциональная декомпозиция, логическое мышление, решение проблем, разработка решений, абстракция и создание повторяемых процессов. Python — один из самых распространенных языков программирования в Data Science (третье место в опросе разработчиков StackOverflow). В данной статье рассматриваются способы интеграции Large Language Models (LLM) в корпоративные системы хранения данных. Основное внимание уделено использованию LLM для автоматического извлечения информации из текстовых данных с последующим формированием SQL-запросов. В рамках исследования также изучаются методы пост-обработки результатов SQL-запросов с целью улучшения точности и адаптивности моделей к конкретным характеристикам и особенностям баз данных.
Лишь в начале 2000-х термин стал общепризнанным в Америке и Европе, а с появлением и распространением хайпа вокруг Big Data традиционная наука о данных получила новое дыхание. Текст будет полезен для разработчиков, решающих схожие задачи по интеграции распределенных фреймворков обработки с реляционными БД, использующих параллельные вычисления. В своей работе часто сталкиваюсь с ситуацией, когда бизнесу нужны метрики и показатели здесь и сейчас, в то время как автоматизация получения и обработки терабайт данных для их расчета может занимать значительное количество времени. Эти специализации отражают широкий спектр применения Big Data и подчеркивают важность разработки моделей данных в современном мире, где объемы информации постоянно растут.
Для разработчика моделей huge information существует возможность обучения онлайн, что позволяет получить необходимые знания и навыки в удобное время и без необходимости посещать офлайн-курсы или учебные заведения. Обучение в университете дает студентам возможность научиться не только техническим аспектам работы с huge data, но и развить навыки коммуникации, аналитического мышления и проблемного мышления. Эти навыки очень важны для разработчиков моделей massive information, так как они должны уметь эффективно взаимодействовать с командой и решать сложные задачи, связанные с обработкой и анализом данных. В рамках обучения в университете разработчики моделей huge information изучают основные принципы хранения, обработки и анализа больших объемов данных. Они учатся работать с различными технологиями и инструментами, используемыми в huge knowledge, такими как Hadoop, Spark, SQL, Python и другие.
В процессе обучения студенты также могут иметь возможность участвовать в проектах и исследованиях, связанных с huge data. Это позволяет им получить практический опыт работы с реальными данными и применить полученные знания на практике. Студенты также изучают методы статистического анализа и машинного обучения, которые позволяют им создавать модели для предсказания и оптимизации данных. Они учатся использовать алгоритмы и техники машинного обучения, чтобы извлекать ценную информацию из больших объемов данных и принимать на их основе стратегические решения. Для того чтобы стать разработчиком моделей huge knowledge, рекомендуется получить высшее образование в области компьютерных наук, математики, статистики или смежных областях. Многие университеты предлагают специализированные программы и курсы, которые позволяют студентам приобрести необходимые знания и навыки для работы с huge data.
Разработчик Massive Knowledge
Изучать инструменты, которые пригодятся в любой задаче Big Data. Этот человек упаковывает все сложные вычисления и технологии в простую форму.Особенность создания интерфейсов аналитических платформ – большое количество параметров данных. Дизайнер делает так, чтобы пользователь по ту сторону экрана мог легко во всем разобраться и запускал собственные исследования без глубокого погружения в предметную область huge data. Здесь наши коллеги создают и развивают платформу Social Analytics. Этот продукт помогает телеком-операторам и бизнесу собирать сырые неструктурированные данные и преобразовывать их в инсайты о клиентах.
